

SQL Server 2012 contains an amazing HA/DR improvement over Database Mirroring technology – AlwaysOn. It provides an ability to split application workflows into Writing and Reading and send them to different SQL Server instances thus improve hardware utilization and increase throughput.
Application can declare the type of queries it executes by adding a connection string keyword “ApplicationIntent“. This keyword is supported by all SQL Server 2012 clients: SQL Server Native Client 11.0 ODBC driver, SQLNCLI11 OLE DB provider, JDBC and SqlClient (ADO.NET). This keyword can have one of two values: ReadOnly or ReadWrite. By default application is considered writing and if nothing is specified in the connection string it’s “ApplicationIntent” is set to “ReadWrite” automatically by the SQL Server client. To be able to utilize readable Secondary replicas of AlwaysOn application must specify ReadOnly application intent in the connection string. Of course, DBA needs to configure readable secondary to accept Read-Only or All connections by executing either one of the following DDL:
ALTER AVAILABILITY GROUP []
MODIFY REPLICA ON N'''' WITH (SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL))or
ALTER AVAILABILITY GROUP []
MODIFY REPLICA ON N'''' WITH (SECONDARY_ROLE(ALLOW_CONNECTIONS = READ_ONLY))Once the SQL Server is configured to accept read-only connections application can connect using a connection string like this:
Server<your secondary replica>;Database=<Availability Group database>;Trusted_Connection=Yes;ApplicationIntent=ReadOnly;To access Primary replica of the Availability Group regardless of which physical machine it is hosted on we added a concept of Availability Group Listener. It maps to Virtual Network (Generic Client Access Point) in the Windows Failover Cluster but is fully under control of the SQL Server. SQL Server can dynamically bind to it when a particular physical machine becomes Primary and unbind from it when machine transitions into the Secondary role. This feature solves a problem of locating Primary replica through an immutable identifier.
In order to access a Secondary replica developers would have to hard-code AlwaysOn replica names in the application connection strings. Obviously it doesn”t work well. After Availability Group failover replicas change roles and Primary becomes Secondary while one of the Secondaries becomes Primary. Primary replica remains addressable by Availability Group Listener but there”s no immutable identifier for one of the Secondary replicas. To resolve this problem and make connectivity experience seamless my team implemented Read-Only Routing feature.
In a nutshell, Read-Only Routing allows redirecting application workflows that only read data to Secondary replicas using Availability Group Listener and Application Intent. From client application perspective only three requirements need to be fulfilled:
- Application must use SQL Server 2012 or later client (that supports TDS 7.4 or above protocol)
- Application connection string must point to Availability Group listener in “Server” keyword. Warning: Pointing application directly to primary replica will bypass read-only routing.
- Application must declare it”s workflow as read-only by adding a connection string keyword “ApplicationIntent” with value “ReadOnly“.
If server is configured correctly application that meets the requirements will be redirected to the secondary replica. A lot more interesting and complicated topic is server-side configuration. I talked to a few customers who embraced AlwaysOn technology and realized that this post is due.
In order for SQL Server to successfully service read-only routing requests the following requirements must be met:
- An Availability Group must have a Listener and all read-only connections should be pointed to it.
- Each Secondary replica must have a valid and correct URL assigned to it.
- Currently Primary replica must have a routing list configured. This list must contain the replicas in routing preference order.
- Secondary replica that is supposed to service read-only requests must be actively synchronizing data with the Primary replica. Warning: If data synchronization is suspended replica is deemed unavailable from Read-Only Routing perspective.
I’d like to stop at each of the points and talk about it.
Availability Group Listener
Listener can be created as part of the new availability group wizard. It is hidden on the last tab of the “Specify Replicas” page.
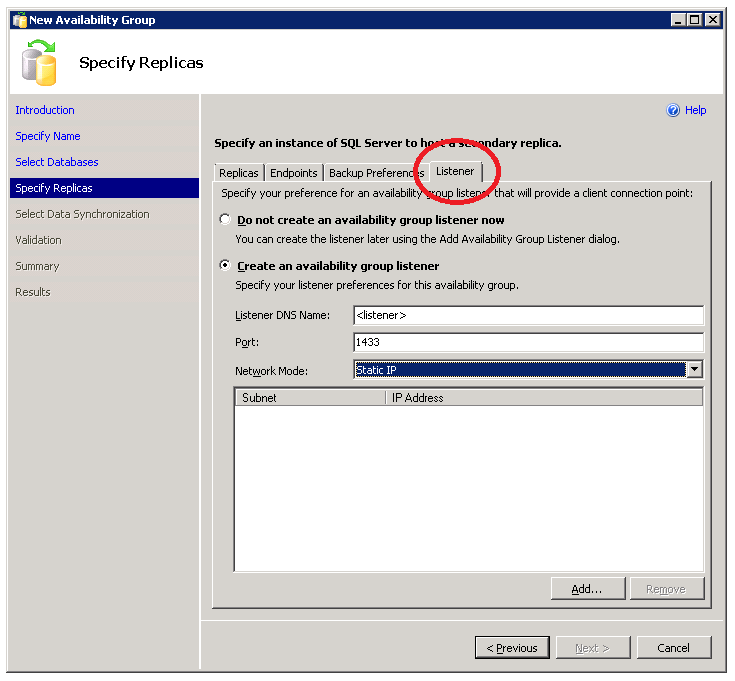
By default it is disabled but I recommend creating a listener with the Availability Group. Listener is the recommended way to access Primary replica. However if you already have an Availability Group but need to add a Listener it can be easily done with the following DDL:
ALTER AVAILABILITY GROUP [<your availability group>]
ADD LISTENER N''<your listener name>'' (
WITH IP
((N''<IP address>'', N''<IP subnet>'')
)
, PORT=<port on which all SQL Server replicas are listening>);To verify that the listener exists and operates correctly you can query the DMVs we”ve added to SQL Server 2012:
select * from sys.availability_group_listeners
select * from sys.availability_group_listener_ip_addressesRead-Only Routing URL
Before Read-Only Routing can be configured each replica must be assigned a valid and correct URL that will be sent to the SQL Server client during routing. People quite often confuse this URL with the Database Mirroring end-point URL. In fact these are two distinct end-points. Database Mirroring end-point is generally configured on port 5022 and is used solely by SQL Server instances to communicate with each other and synchronize data. Read-Only Routing URL on the other hand is a URL that can be used by SQL Server client to connect to SQL Server instance. The port in Read-Only Routing URL is a TCP port at which SQL Server has a TDS end-point. By default it is 1433.
Syntax for configuring Read-Only Routing URL:
ALTER AVAILABILITY GROUP [<your availability group>]
MODIFY REPLICA ON N''<your availability group replica>'' WITH (SECONDARY_ROLE(READ_ONLY_ROUTING_URL=N''tcp://<host>:<port>''))Please note that the URL is under SECONDARY_ROLE option. If replica is currently Primary you still need to configure it”s READ_ONLY_ROUTING_URL under SECONDARY_ROLE.
The format of the URL must follow regular URL specification = <protocol>://<host>:<port>. There might be a confusion since SQL Server clients support a different format of the URL in the connection string – <protocol>:<host>[,<port>]. Please use regular URL format when configuring Read-Only Routing on the server and disregard the other format that SQL Server clients understand.
SQL Server currently supports 4 ways to specify the target replica in the URL:
- Fully qualified domain name. For example – tcp://myreplica.mydomain.com:1433. This is the recommended way.
- Relative domain name – tcp://myreplica:1433
- IP v4 address – tcp://10.0.2.3:1433
- IP v6 address – tcp://[2001:4898:f0:f020:79ee:9e2f:4319:60b6]:1433
To check which URL is assigned to the replica please query the column in a catalog view:
select read_only_routing_url from sys.availability_replicasNOTE: SQL Server will fail Read-Only Routing configuration if at least one of the replicas in the Read-Only Routing List doesn’t have a URL.
Read-Only Routing List
It is a list of replicas in the order of preference that Primary replica should evaluate whenever it receives a readable connection request and redirect the client to the first replica from the list that can serve the request. It is not a random distribution list accross all secondary replicas. We counciously decided not to implement random distribution because many applications expect consistent “view of the world” across connections. This isn’t possible with random distribution accross multiple asynchronous replicas that are at different points of transactional commit.
ALTER AVAILABILITY GROUP [<your availabiliry group>]
MODIFY REPLICA ON N''<your availability group replica>'' WITH (PRIMARY_ROLE(READ_ONLY_ROUTING_LIST = (N''<first preference replica>'', N''<second preference replica>'')))Please note that READ_ONLY_ROUTING_LIST is under PRIMARY_ROLE configuration section of the replica. If replica is currently in Secondary role it is strongly advised to configure Read-Only Routing List for it as well in case failover happens to preserve readable workload. Without Read-Only Routing List configured for would-be Primary readable workload would be cut off after failover.
To see all read-only routing lists that are visible to the replica on which you run the query, you can execute this:
select * from sys.availability_read_only_routing_listsObviously, to get a view per Availability Group this catalog view would have be joined with other catalog views. For example the following query will return human-readable view of the routing configuration for all Availability Groups:
select g.name, r1.replica_server_name, l.routing_priority, r2.replica_server_name, r2.read_only_routing_url
from sys.availability_read_only_routing_lists as l
join sys.availability_replicas as r1 on l.replica_id = r1.replica_id
join sys.availability_replicas as r2 on l.read_only_replica_id = r2.replica_id
join sys.availability_groups as g on r1.group_id = g.group_idIf everything is done correctly Read-Only Routing should be up and running by now. Let’s pretend that it isn’t and try to troubleshoot it.
Database Synchronization State
If Secondary replica isn’t synchronizing data with the Primary it will not be considered by the Primary as a routing candidate even if it is in the Read-Only Routing List.
If database on the Secondary replica has a little “pause” sign next to it in SQL Server Management Studio object explorer it means it is not synchronizing data. Data synchronization can be resumed right-clicking on the database and choosing “Resume Data Movement…”
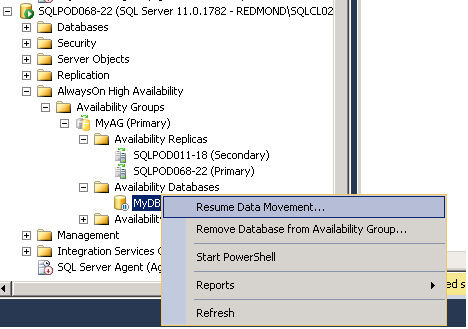
From the T-SQL script it can be done executing the following DDL on the replica that isn’t synchronizing:
ALTER DATABASE <database> SET HADR RESUMEOnce data movement is resumed Primary replica will activate routing to the Secondary replica of interest.
Extended Events
To help troubleshoot Read-Only Routing beyond obvious problems we added 3 events to the SQL Server. They are hidden under “Debug” channel of the Extended Events Session dialog.
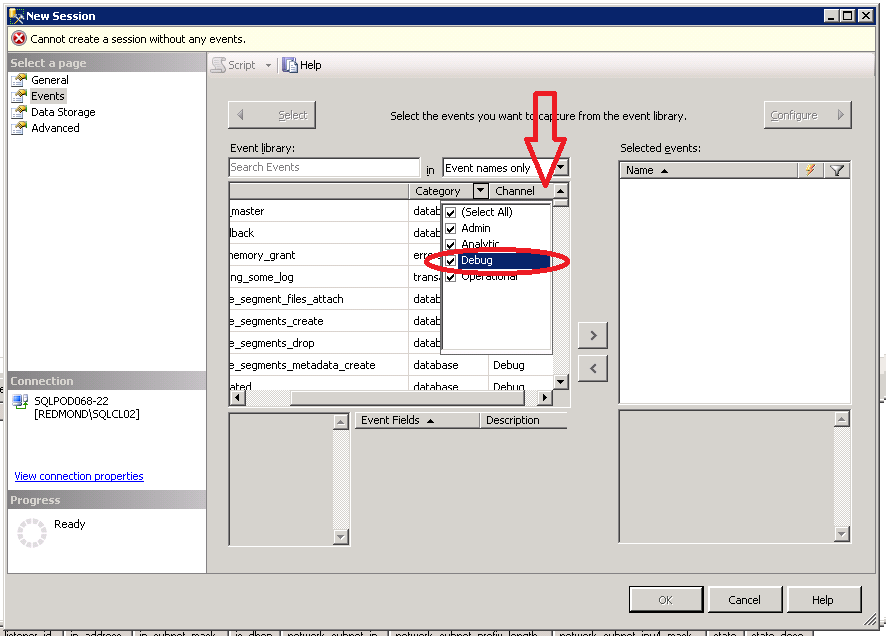
To access them please click a little drop-down box on the “Channel” column and check “Debug“. Please add following events:
- read_only_route_complete is registered on the Primary replica when it successfully routes the client to the URL provided in the Secondary replica that was selected by the Primary replica.
- read_only_route_failed is fired when Primary replica couldn”t find a single viable candidate for routing
- hadr_evaluate_readonly_routing event is fired on the Primary replica whenever Availability Group state changes and it needs to re-evaluate the routing target from the list. This can happen when Availability Group fails over, one of the replicas change their connectivity policy (e.g. Read-Only to No), Read-Only Routing List changes, etc. No client connections are necessary for this event to occur. Pure server-side changes trigger it.
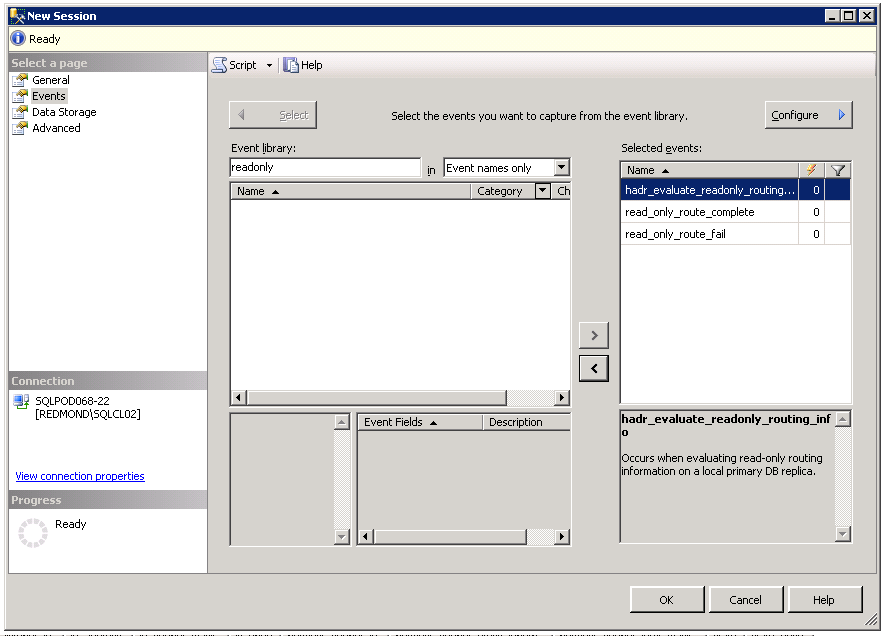
Using these 3 events one can very easily troubleshoot routing problems.
One very common mistake that people make is they generate wrong but valid Read-Only Routing URLs. Tripple-check that your URLs contain correct representations of the host on which SQL Server is running and most importantly the port number. To see which ports SQL Server is listening on one can use SQL Server Configuration Manager or SQL Server logs. Both places contain port numbers. Make sure that these port numbers are reflected in the routing URLs. One clear indication of incorrect URL is when Primary replica fires read_only_route_complete but for some reason client’s get connection timeout errors.
Command-Line Tools
We added Read-Only Routing support to SQLCMD.exe tool through -K command-line option. To use it simply specify application intent prefixed by -K. For example:
SQLCMD.exe -S <your availability group listener> -D <availability group database> -E -K ReadOnlySQLCMD tool will connect to the availabiliy group listener and pass it’s ReadOnly intent which will trigger Read-Only Routing and the tool will be redirected to the Secondary replica which accepts read-only workflow.
Lastly, if you’re enjoying Read-Only Routing in your enterprise and it works perfectly I”d love to hear your feedback. On the other hand if you have any troubles with Read-Only Routing I would like to hear them as well and help you get a quick and reasonable resolution. Stay tuned for updates and trick.
FAQ
Q: When porting applications to SQL Server AlwaysOn is it application”s responsibility to figure out which replica to send the query to or will SQL Server route the requests automatically depending on the query?
A: Short answer – SQL Server will figure it out. Let me also give a long answer to help understand the whys and hows. Read-Only Routing is connection-level feature, not a query-level. If a read-only query is sent via a connection with ApplicationIntent = ReadWrite it will not be routed to the secondary replica, because by the time the query is sent connection will already have been routed. Routing occurs during login phase, before any query is sent to the server.
If an application combines two types of workflows (read-only and read-write) then it is application”s responsibility to open two connections: the first with ApplicationIntent = ReadWrite and the second one with ApplicationIntent = ReadOnly. Reading queries should be sent via the second connection while writing via the first.
Developer and DBA should be mindful of a subtle yet very important aspect of AlwaysOn. There are 2 modes of data synchronization between Primary and Secondary replicas: Synchronous and Asynchronous:
- In Synchronous mode, both Primary and Secondary replicas view the data at the same time the same way. Basically the operation is committed only when both Primary and Secondary replicas commiited. In this mode of replication it is safe to send read-only queries via a separate connection because they will be able to pick up the results of the read-write queries immediately
- In Asynchronous replication mode, Secondary replica is applying transaction log with a delay and can theoretically fall behind a Primary for more than a few seconds. If an application that has just inserted a data into the Primary replica (via ReadWrite connection) queries for it on the Secondary it may not find it since the transaction log hasn’t been committed yet on the Secondary replica. In this case it isn’t generally safe to split a single application into two workflows. However in certain scenarios this is acceptable if application doesn’t make any assuptions about data availability between reads and writes.
Q: What algorithm(s) does the ReadOnly connection router use when ApplicationIntent=ReadOnly?
A: We’ve built a foundation for connection routing. This was a first iteration of functionality and doesn”t include all the features we”d like. For example, in future we may add resource governance to connection routing. It might even be possible to configure entirely custom routing algorithm, including random or event normal distribution. We received numerous comments about the types of algorithms customers would like to use for their solutions.
Going back to your question – the only algorithm that is currently supported is sequential traversal of the routing list to the end. It is not a round-robin in a sense that it doesn”t wrap around when the end of the list is reached. Primary replica strictly traverses the list and looks for the first replica that can serve the connection request. Once found, all subsequent read-only connections are routed to it. Only availability group state changes (e.g. failover, replica state change, etc.) can cause read-only target recalculation.
We recognize that this algorithm is limited. Please keep in mind that it serves it’s purpose – keep the read-only applications running. If we introduced random distribution or even round-robin, it could have broken numerous applications, that establish multiple independent connections and expect data to be consistent across all of them. If primary replica were choosing different replicas upon each request, then not only it would increase load on the primary replica, it would also result in different connections going to different replicas and thus having different view of the world due to asynchronous data replication between instances.