Nearly every application developer on planet Earth that has a web service and a database, has faced this problem. How to upgrade a database and an application that expects a specific database schema in such a way that the application is not broken at any point in time during an upgrade? We are talking relational databases here – SQL Server, MySql, Postgres, Oracle, and alike. If you are a NoSql guy or a girl and think you got it easy, I will wait for you right here, in this article, until your database gets to 1 TB. Over my career, I have seen a number of ways application developers dealt with database upgrades. I decided to put them all together under one roof as a reference guide for young generations.
What’s the problem?
Traditional 2-tier and 3-tier architectures prescribe separation of compute tier from state on a different cluster of machines to allow each tier to scale independently. In plain English, your web server runs on a different computer than your database.
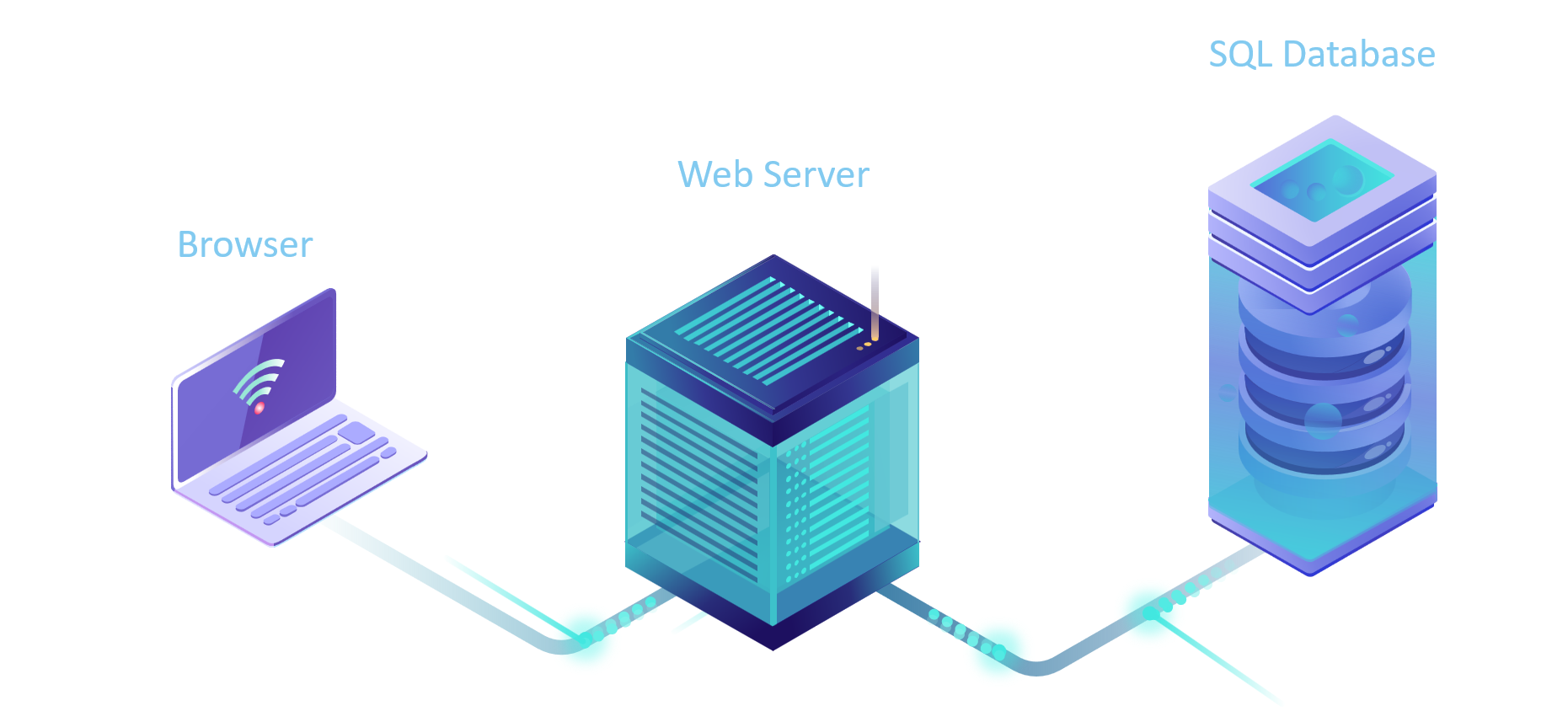
In real-world deployments, there are multiple web servers and multiple databases serving different customers from all over the world. As such, there is more than one web server and SQL database to upgrade. Customers are using this system any time of day and night so it is not practical to take the whole set of machines offline, upgrade and bring back into rotation. This used to be acceptable in the 1990-ties but in this day and age, no customers would tolerate intentional system downtime. Well, almost no customers…
To demonstrate the problem in action we will need a piece of code and a database. Lets say we have a database table with the schema defined below.
CREATE TABLE dbo.PurchaseOrderDetail
(
PurchaseOrderID int NOT NULL,
LineNumber smallint NOT NULL,
ProductID int NULL,
UnitPrice money NULL,
OrderQty smallint NULL,
ReceivedQty float NULL,
RejectedQty float NULL,
DueDate datetime NULL,
rowguid uniqueidentifier ROWGUIDCOL NOT NULL
CONSTRAINT DF_PurchaseOrderDetail_rowguid DEFAULT (NEWID()),
ModifiedDate datetime NOT NULL
CONSTRAINT DF_PurchaseOrderDetail_ModifiedDate DEFAULT (GETDATE())
)We will need a class to describe this object in our application tier. Most applications hydrate database state into an object in memory so this is a typical behavior of an application.
internal sealed class PurchaseOrderDetail
{
public int PurchaseOrderID { get; set; }
public short LineNumber { get; set; }
public int? ProductID { get; set; }
public decimal? UnitPrice { get; set; }
public short? OrderQty { get; set; }
public double? ReceivedQty { get; set; }
public double? RejectedQty { get; set; }
public DateTime? DueDate { get; set; }
public Guid rowguid { get; set; }
public DateTime ModifiedDate { get; set; }
}We will also need a method to read this table from the database.
public static IList<PurchaseOrderDetail> GetOrderDetails(IDbConnection connection)
{
IList<PurchaseOrderDetail> results = new List<PurchaseOrderDetail>();
using (IDbCommand command = connection.CreateCommand())
{
command.CommandText = @"SELECT TOP 100
[PurchaseOrderID],
[LineNumber],
[ProductID],
[UnitPrice],
[OrderQty],
[ReceivedQty],
[RejectedQty],
[DueDate],
[rowguid],
[ModifiedDate]
FROM [olegdb].[dbo].[PurchaseOrderDetail]";
using (IDataReader reader = command.ExecuteReader())
{
while (reader.Read())
{
results.Add(new PurchaseOrderDetail()
{
PurchaseOrderID = reader.GetInt32(0),
LineNumber = reader.GetInt16(1),
ProductID = reader.GetInt32(2),
UnitPrice = reader.GetDecimal(3),
OrderQty = reader.GetInt16(4),
ReceivedQty = reader.GetDouble(5),
RejectedQty = reader.GetDouble(6),
DueDate = reader.GetDateTime(7),
rowguid = reader.GetGuid(8),
ModifiedDate = reader.GetDateTime(9),
});
}
}
}
return results;
}The code is efficient – it reads only what it needs from the database and it references specific columns in the table by name to avoid ambiguity. This code is running in production and everyone is happy with the intuitive interface and snappy performance.
Schema change
Everything is fine until one day the application developer decides to change one of the columns in the table. Let’s say ProductID is being converted from an “int” into a “uniqueidentifier” for compatibility with another system. That makes the table create statement look as follows.
CREATE TABLE dbo.PurchaseOrderDetail
(
/* ... */
ProductID uniqueidentifier NULL, /* This has changed from int */
/* ... */
)This requires corresponding changes in our application tier as well. We need to change the type of the class property.
internal sealed class PurchaseOrderDetail
{
/* ... */
public Guid? ProductID { get; set; } /* This used to be int */
/* ... */
}Since the type has changed we need to modify our reader code to use the right accessor method on IDataReader.
results.Add(new PurchaseOrderDetail()
{
/* ... */
ProductID = reader.GetGuid(2), /* This was GetInt32() */
/* ... */
});Of course, the application developer also writes a piece of T-SQL code to migrate data from the old column into the new one. He/she understands that data doesn’t magically move in the new column only because he or she changed table definition. Since there is no straight-forward conversion from an “int” into a “uniqueidentifier“, the application developer has to write a bit of transformation script.
BEGIN TRANSACTION
GO
/* Create a new table with a new schema */
CREATE TABLE dbo.PurchaseOrderDetail_v2
(
PurchaseOrderID int NOT NULL,
LineNumber smallint NOT NULL,
ProductID uniqueidentifier NULL, /* This is changing int -> uniqueidentifier */
UnitPrice money NULL,
OrderQty smallint NULL,
ReceivedQty float NULL,
RejectedQty float NULL,
DueDate datetime NULL,
rowguid uniqueidentifier ROWGUIDCOL NOT NULL
CONSTRAINT DF_PurchaseOrderDetail_rowguid DEFAULT (NEWID()),
ModifiedDate datetime NOT NULL
CONSTRAINT DF_PurchaseOrderDetail_ModifiedDate DEFAULT (GETDATE())
)
GO
/* Create a temporary table to contain converted data from the old table */
SELECT [PurchaseOrderID]
,[LineNumber]
,CONVERT(uniqueidentifier, CONVERT(VARBINARY(MAX), [ProductID])) as ProductID
,[UnitPrice]
,[OrderQty]
,[ReceivedQty]
,[RejectedQty]
,[DueDate]
,[rowguid]
,[ModifiedDate],
INTO [#PurchaseOrderDetail_temp]
FROM [olegdb].[dbo].[PurchaseOrderDetail]
GO
/* Copy the data */
SELECT *
INTO [olegdb].[dbo].[PurchaseOrderDetail_v2]
FROM [#PurchaseOrderDetail_temp]
GO
/* Get rid of a temporary table */
DROP TABLE [#PurchaseOrderDetail_temp]
GO
/* Drop the old table with the data in "int" type */
DROP TABLE [olegdb].[dbo].[PurchaseOrderDetail]
GO
/* Rename the new table into the old table name that application expects */
EXEC sp_rename '[PurchaseOrderDetail_v2]', '[PurchaseOrderDetail]'
GO
COMMIT TRANSACTION
GOInteresting question becomes – should this developer upgrade an application or a database first to ensure that at no point in time application is broken?
Database goes first
If developer decides to apply database schema changes first before upgrading an application then application will be broken for a period of time. Application users will likely see an exception
System.InvalidCastException: Specified cast is not valid.
at System.Data.SqlClient.SqlBuffer.get_Int32()
at System.Data.SqlClient.SqlDataReader.GetInt32(Int32 i)
at OlegApplication.Program.GetOrderDetails(IDbConnection connection) in c:\users\oleg\OlegApplication\Program.cs:line 49
This will happen when reading “ProductID” as an integer type in the old code:
results.Add(new PurchaseOrderDetail()
{
/* ... */
ProductID = reader.GetInt32(2), /* In the database this type is already a uniqueidentifier */
/* ... */
});As such, database first then application is not a good upgrade strategy.
Application goes first
Another strategy might be to try upgrading an application before database. Unfortunately this won’t be any better user experience-wise.
System.InvalidCastException: Specified cast is not valid.
at System.Data.SqlClient.SqlBuffer.get_SqlGuid()
at System.Data.SqlClient.SqlDataReader.GetGuid(Int32 i)
at OlegApplication.Program.GetOrderDetails(IDbConnection connection) in c:\users\oleg\OlegApplication\OlegApplication\Program.cs:line 49This will happen when reading the same “ProductID” as a unique identifier type in the new code:
results.Add(new PurchaseOrderDetail()
{
/* ... */
ProductID = reader.GetGuid(2), /* This is still an integer in the database */
/* ... */
});Seems like application upgrade followed by a database upgrade is not a good strategy either.
What gives? This brings us to the point of this article – how to implement an application and a database such that users are unaffected during upgrade phases.
Strategy 1: Database schema versioning
The most flexible way to coordinate database and application upgrades if via a handshake. The idea is that an application is backward-compatible with multiple versions of the database schema and is the first to upgrade at all times. An application can discover database schema at any point in time and adjust behavior. In most cases, single version compatibility is sufficient, but in some cases, an application developer can choose to support multiple versions. This can happen when he or she doesn’t control database schema upgrade frequency and should expect any drift between application and database.
First, we need a way for a database to tell the application which version it is running. For that, we will need a stored procedure that returns a single value – the version number of the entire database schema.
CREATE PROCEDURE [dbo].[GetDatabaseVersion] AS
SELECT 1Entire database is upgraded atomically and as part of that upgrade our procedure will be upgraded to return different version number. If we incorporate this strategy into our database upgrade script above it would look as follows.
BEGIN TRANSACTION
GO
/* ... Execute schema upgrade script ... */
/* Change our stored procedure to return a higher version number */
ALTER PROCEDURE [dbo].[GetDatabaseVersion] AS
SELECT 2
GO
COMMIT TRANSACTION
GONow we need to change our application to read the database schema version. First, we need a simple method that returns the schema version number from the database.
public static int GetDatabaseVersion(IDbConnection connection)
{
using (IDbCommand command = connection.CreateCommand())
{
command.CommandText = "[dbo].[GetDatabaseVersion]";
command.CommandType = CommandType.StoredProcedure;
return (int)command.ExecuteScalar();
}
}Some short-lived applications that are spun up to do a task and terminate quickly don’t need any special handling and can read database schema version when they start.
static void Main(string[] args)
{
using (SqlConnection connection = new SqlConnection("..."))
{
connection.Open();
// Read the schema version
int databaseVersion = Program.GetDatabaseVersion(connection);
// Interact with the database depending in the schema version
IList<PurchaseOrderDetail> orders = Program.GetOrderDetails(connection, databaseVersion);
}
Console.WriteLine("Done");
}However, for a more complicated application with a multitude of transactions constantly running against the database, checking schema version only once or even at regular frequency would not cut it. Since it is not possible to coordinate the exact moment of schema upgrade and the start of a particular transaction, race conditions are guaranteed. To deal with this, an application developer can incorporate schema change detection into retry logic in failure conditions.
static void Main(string[] args)
{
using (SqlConnection connection = new SqlConnection("..."))
{
connection.Open();
int databaseVersion = GetDatabaseVersion(connection);
// This loop is just to convey the point
// Real application should use retry library with policies and strategies
int retryRemain = 3;
while (retryRemain > 0)
{
try
{
IList<PurchaseOrderDetail> orders = Program.GetOrderDetails(connection, databaseVersion);
break;
}
catch (SqlException e)
{
// Refresh schema on SQL error
databaseVersion = GetDatabaseVersion(connection);
// Decrement retry attempts
retryRemain--;
}
catch (InvalidCastException)
{
// Refresh schema on cast error
databaseVersion = GetDatabaseVersion(connection);
// Decrement retry attempts
retryRemain--;
}
}
}
Console.WriteLine("Done");
}This application would read the schema version when it starts and assume that schema doesn’t change over the life span of an application. However, if it encounters an error, it will assume that it is caused by schema incompatibility. In this case it will attempt to correct the error by refreshing database schema version and rerunning the same transaction again. Application needs to expect both SQL server error and .NET exceptions since either of those can be caused by schema incompatibility. To improve application correctness, application developer can add an if statement under SqlException catch clause to expect specific problems that pertain to given transaction – e.g. column not found, table not found, etc.
Orchestration
Application written according to the first strategy will require a 2-phase upgrade. Before upgrade starts both the application and the database are compatible and running on the same version.
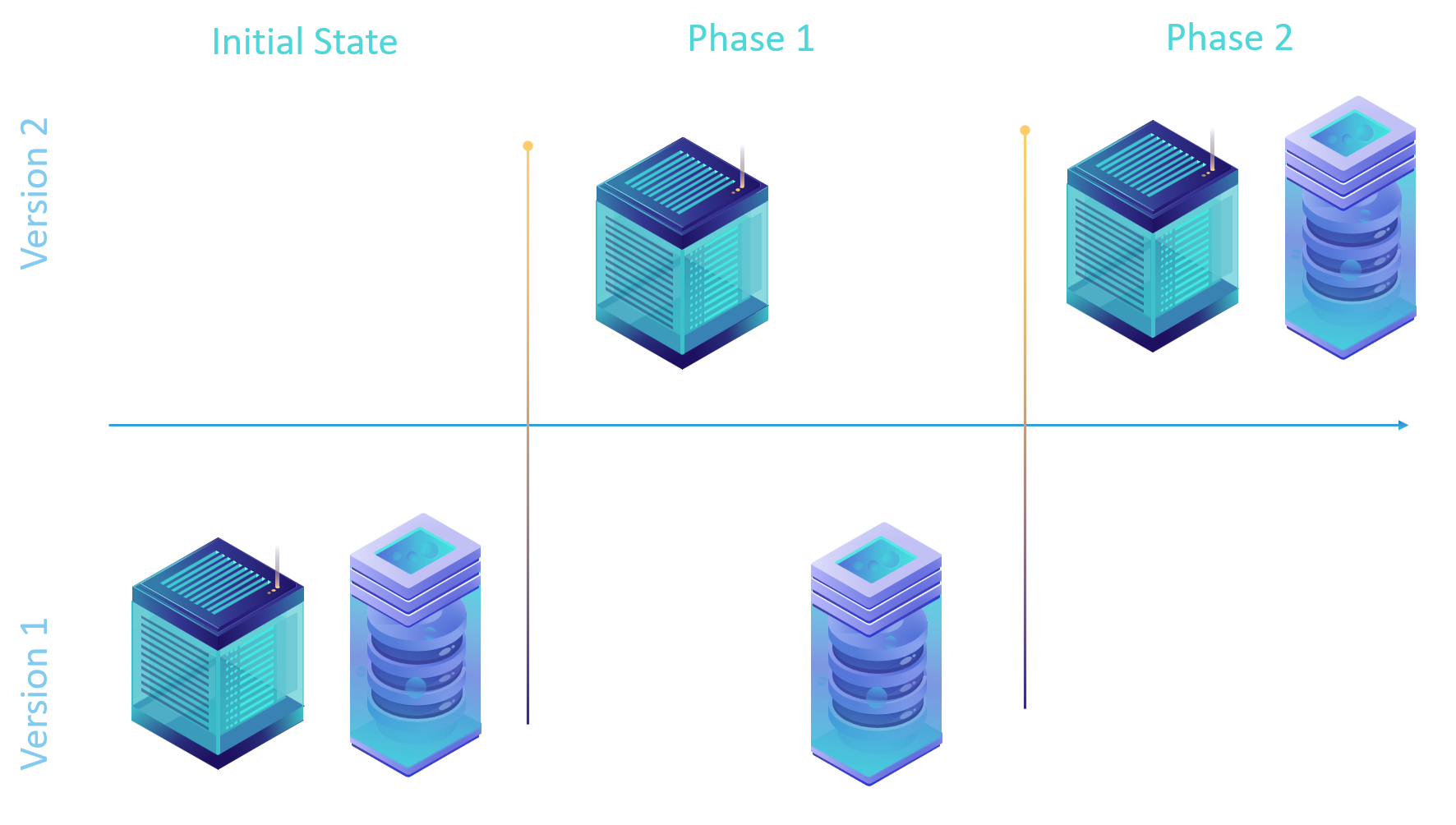
The first upgrade phase requires that the application is upgraded but the database kept on the old version. This allows the application to prepare for the upcoming database upgrade but not change it’s behavior yet. The application needs to be deployed first because the database contains the handshake function that determines how the application behaves. If the database is upgraded before application then the older application version will not recognize a higher database version and will fail to handle it correctly.
It is not recommended to upgrade both the application and the database at the same time because race condition may occur in which the database runs at a higher version than the application which would lead to failure.
The second upgrade phase brings the database up to the latest version and causes the application to change its behavior based on the new number returned by GetDatabaseVersion stored procedure.
After the second upgrade phase, a subsequent application upgrade can remove code in the application that expects version 1 of the database. Historically I have seen developers forget this part and leave old code in the application running, which complicates code and increases the margin of error. So it is highly recommended to clean up your application code after all applications and database instances are upgraded worldwide.
Strategy 2: Database object schema versioning
Another strategy to coordinate database and application upgrade is to pin a specific application version to a specific database schema. There is no need to track a version number via a stored procedure call, but a version of the schema is embedded into every database object that application touches. An application can explicitly request a specific version of the database object simply by appending the version to the object name. This makes the database capable of supporting a range of application versions simultaneously.
The trick to achieving schema versioning is to separate data from presentation layer. Application should no longer access tables directly, but rather use views on top of those tables. It is fine to access stored procedures directly since they don’t contain data, but rather stateless code that can also be versioned.
Lets create a view for our initial table in question.
CREATE VIEW PurchaseOrderDetailView_v1 AS
SELECT PurchaseOrderID,
LineNumber,
ProductID,
UnitPrice,
OrderQty,
ReceivedQty,
RejectedQty,
DueDate,
rowguid,
ModifiedDate FROM dbo.PurchaseOrderDetail;
GO
Now we need to modify our application to access the view rather than table directly.
public static IList<PurchaseOrderDetail> GetOrderDetails(IDbConnection connection)
{
/* ... */
command.CommandText = @"SELECT TOP 100
[PurchaseOrderID],
[LineNumber],
[ProductID],
[UnitPrice],
[OrderQty],
[ReceivedQty],
[RejectedQty],
[DueDate],
[rowguid],
[ModifiedDate]
FROM [olegdb].[dbo].[PurchaseOrderDetailView_v1]"; /* We are referencing a view instead of the table and pinning a specific version */
/* ... */
}The functionality of the application is unaffected, but we gained a level of indirection that allows us to swap the view in the next version of the database schema. Let’s say our application developer needs to evolve this view to return a different type for a ProductID column, just like in the example for the previous strategy.
BEGIN TRANSACTION
GO
/* Create a new version of the view that returns a new type for a column */
CREATE VIEW PurchaseOrderDetailView_v2 AS
SELECT PurchaseOrderID,
LineNumber,
CONVERT(uniqueidentifier, CONVERT(VARBINARY(MAX), [ProductID])) as ProductID,
UnitPrice,
OrderQty,
ReceivedQty,
RejectedQty,
DueDate,
rowguid,
ModifiedDate FROM dbo.PurchaseOrderDetail;
GO
COMMIT TRANSACTION
GOWhen this upgrade transaction runs it has no affect on the behavior of existing running applications. It is simply an additive change that no one takes advantage of for now. Application developer wants to take advantage of this new view in his code directly.
public static IList<PurchaseOrderDetail> GetOrderDetails(IDbConnection connection)
{
/* ... */
command.CommandText = @"SELECT TOP 100
[PurchaseOrderID],
[LineNumber],
[ProductID],
[UnitPrice],
[OrderQty],
[ReceivedQty],
[RejectedQty],
[DueDate],
[rowguid],
[ModifiedDate]
FROM [olegdb].[dbo].[PurchaseOrderDetailView_v2]"; /* We are explicitly referencing a new version of the view */
/* ... */
}Orchestration
This schema version coordination strategy requires database upgrade and application to go in specific order. If application and database upgrades are kicked off at the same time, a race condition can occur leading to transient application failures.
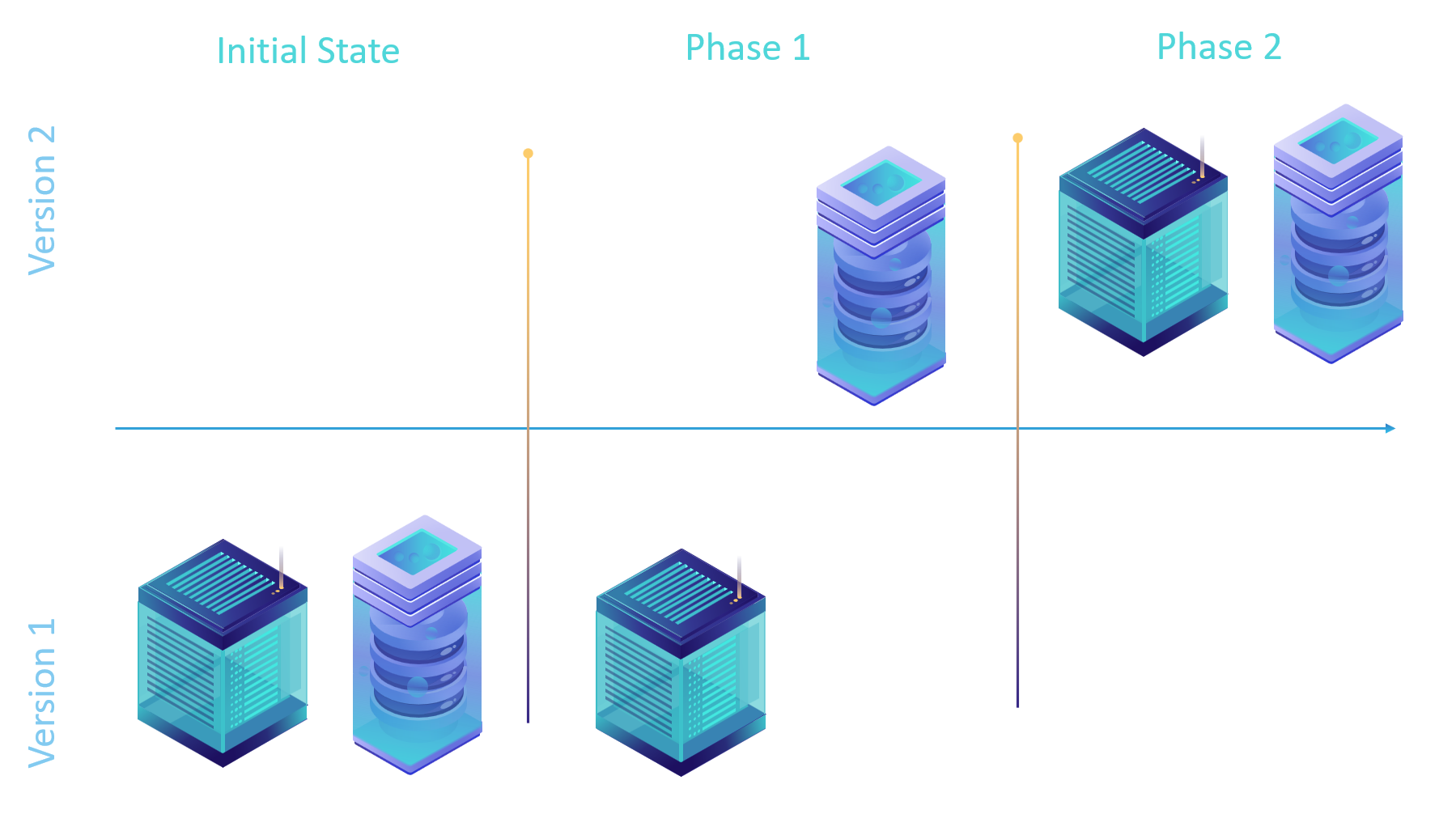
The first upgrade phase requires that the database is upgraded but the application is left on the current version. This is done because database is backwards compatible but application is not.
The second upgrade phase brings the application to the next version which allows it to take advantage of new capabilities of the database. Since the database can support multiple application versions, it doesn’t have to be the latest application version.
The challenge of this model is to know when it is safe to discontinue support for a specific database schema version. If the developer controls all application instances then it is an easy task. However, if applications are distributed among multiple sites and are controlled by different people there will be a need for deprecation policy.
Another challenge of this model is to know when to perform a data migration into a newer table format. Building more views on top of the same data eventually will result in a significant compute overhead and a lack of ability to build indexes on top of data. It is not practical to keep data in the same table forever. At some point application developer will need to bite the bullet and transform the table into a more suitable format.
Strategy 3: Database schema is backward compatible
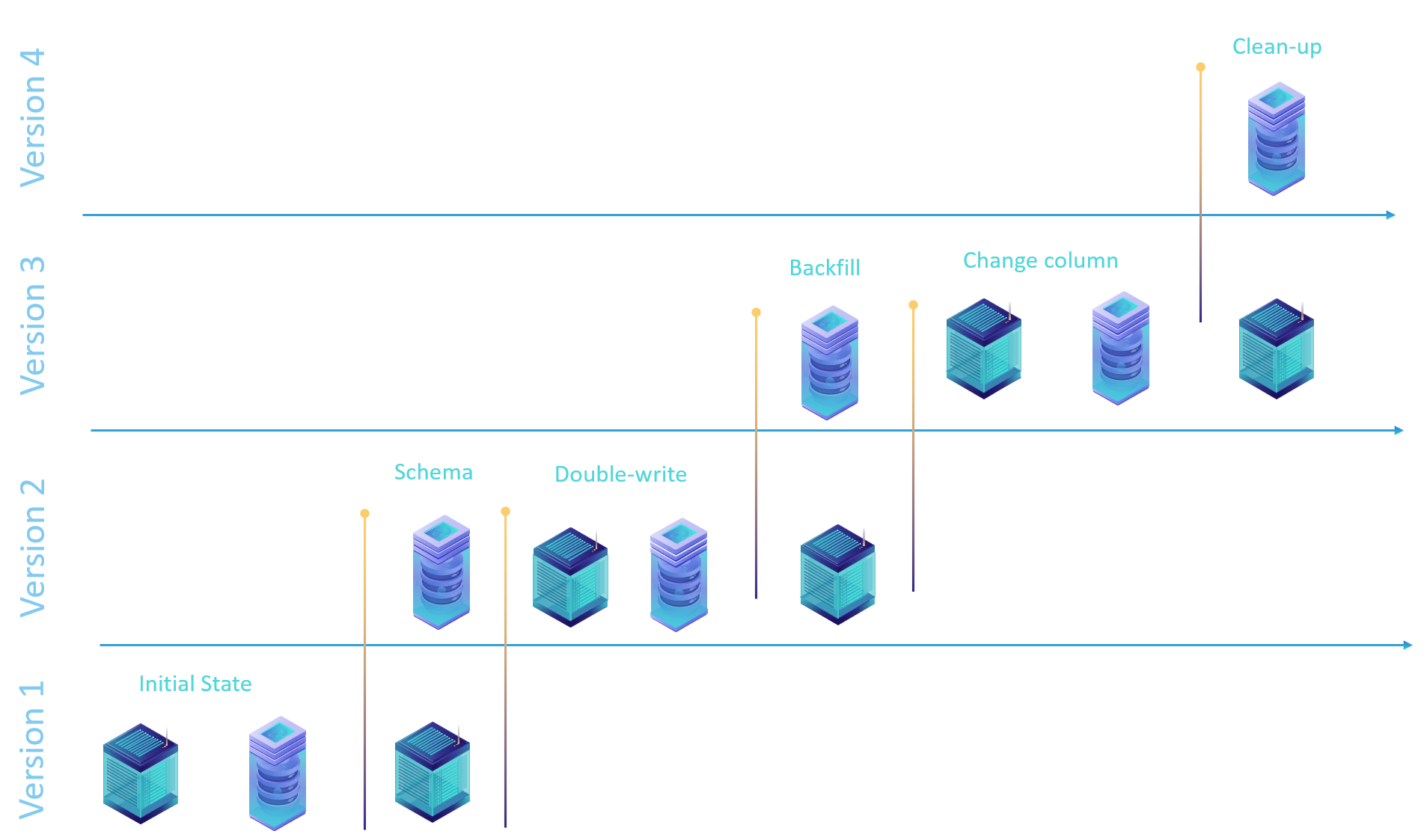
If you have an existing application and the adoption cost of either schema versioning strategy above is high, there is a path forward for your schema evolution, without boiling the ocean. The idea is to modify schema in a way that preserves compatibility with two or more application versions. This strategy has limitations and leads to data and code duplication, but is perfectly adequate for a controlled schema change. I would not recommend this as a general pattern because it has higher operational overhead (more expensive, more engineering, has consistency problems, etc.). This model also has a much higher orchestration cost which means it will take longer to complete, as we will see below.
Orchestration
Let’s go back to our problem of having to change the type of ProductID column from “int” to “uniqueidentifier“. To preserve schema-compatibility with existing application we need to add a new column with a new type at the end of the table.
BEGIN TRANSACTION
GO
/* Add a column to existing table at the end */
ALTER TABLE dbo.PurchaseOrderDetail
ADD ProductIDGuid uniqueidentifier NULL; /* This is a new column for a new data type int -> uniqueidentifier */
GO
COMMIT TRANSACTION
GOWhen this upgrade script runs, it will create a new column and populate it with data that existed in the original column at that time. Notice we are not copying the data – only creating a new column. This is done intentionally because for applications with high throughput any data copied in this transaction would be stale by the time this transaction commits. We will address this problem next.
The first upgrade phase which includes the only schema needs to be deployed to all production databases before any code can change. There is a very explicit dependency between code and application. Careful coordination is required between deployments and application changes. It is not possible to just be “code complete” for both application and schema change and simply deploy them in a particular order.
The application needs to be modified to “write” data into the new column but not “read”. This is done to start populating data in the new column for any drift between subsequent schema upgrade and back-fill. Let’s break that down.
Back-fill and catch-up
There will be a point in time when we execute a transaction to create a new column.
- We want all data that exist in the original column before this transaction to appear in the new column atomically.
- We also want all new data that is inserted into the old column to also be inserted into the new column.
There are two obvious problems:
- There will be traffic to the database while ALTER TABLE T-SQL statement is running. So even though ALTER TABLE is atomic, it is not possible to also atomically pick up every single record from the table with UPDATE statement to copy data. There will be misses that will lead to data loss, which is unacceptable.
- Insertion of data into new column is an application problem, while back-fill of existing data from existing column into the new one is a database problem. We have already established that it is not possible to coordinate application and database upgrade to the point of a single transaction in the database. So we shouldn’t even try. If we try, we will have a data loss.
Double-write
To avoid gaps we need to modify our application to start writing data into ProductIDGuid and ProductID simultaneously. Our object that represents database table record needs to have two properties that we are writing
The second upgrade phase should contain only application code that starts writing into both columns simultaneously must be deployed worldwide to make sure that no application instance is writing a single column anywhere.
Back-fill
internal sealed class PurchaseOrderDetail
{
/* ... */
public int? ProductID { get; set; }
/* ... */
public Guid? ProductIDGuid { get; set; }
}
/* ... */
public static void CreasteOrderDetails(IDbConnection connection, PurchaseOrderDetail purchaseOrderDetail)
{
using (IDbCommand command = connection.CreateCommand())
{
command.CommandText = @"INSERT INTO [olegdb].[dbo].[PurchaseOrderDetail] (
[PurchaseOrderID],
[LineNumber],
[ProductID],
[UnitPrice],
[OrderQty],
[ReceivedQty],
[RejectedQty],
[DueDate],
[rowguid],
[ModifiedDate],
[ProductIDGuid])
VALUES (
@PurchaseOrderID,
@LineNumber,
@ProductID,
@UnitPrice,
@OrderQty,
@ReceivedQty,
@RejectedQty,
@DueDate,
@rowguid,
@ModifiedDate,
@ProductIDGuid)";
/* ... */
command.Parameters.AddWithValue("@ProductID", purchaseOrderDetail.ProductID);
command.Parameters.AddWithValue("@ProductIDGuid", purchaseOrderDetail.ProductIDGuid);
/* ... */
command.ExecuteNonQuery();
}
}Now that all new transactions are being written with both values it is safe to perform data back-fill. We can copy all existing values into the new column and sleep well knowing there are no gaps in data.
BEGIN TRANSACTION
GO
/* Copy the data */
UPDATE dbo.PurchaseOrderDetail
SET ProductIDGuid = CONVERT(uniqueidentifier, CONVERT(VARBINARY(MAX), [ProductID]))
COMMIT TRANSACTION
GOThe third upgrade phase will apply only to the database tier and contain only back-fill. When this phase is complete it is very simple to check if we have any gaps and if we do – investigate where they are coming from.
SELECT TOP 10 *
FROM dbo.PurchaseOrderDetail
WHERE ProductIDGuid IS NOT NULL AND ProductIDGuid IS NULL
GOIt is recommended to “bake” in this phase for at least a few days to make sure that really no applications are missing the data and everything is consistent. The query above should be run periodically to check for drift.
Change column role
At this point, both columns are consistent but the old column “ProductID” is still treated “primary” source of information, while “ProductIDGuid” is made to match the value. It is time to switch them around. Look for all places in the source code that references “ProductID” and replace them with “ProductIDGuid“. It is OK to stop writing the “ProductID” column altogether as part of this change.
First we can remove this column from our class representing database record.
internal sealed class PurchaseOrderDetail
{
/*
* This column is no longer needed
*
public int? ProductID { get; set; }
*/
/* ... */
public Guid? ProductIDGuid { get; set; }
}We should also go through all consumers of this class and replace one column with another. The compiler will help identify those places as the code will break during the build. If you are using reflection you’ll have to do a string search and replace and run all your functional tests to make sure code continues to function.
The fourth upgrade phase will contain only the application code while the database remains the same. This is the last functional change for the application and will achieve the desired database schema without breaking user experience.
Clean-up
When application switched to ProductIDGuid you are left with an old ProductID column in the table with partial data. You can do one of two things, depending on your tolerance level for imperfection and desire to deal with the maintenance of this column on the storage layer.
BEGIN TRANSACTION
GO
/* Reset old data */
UPDATE dbo.PurchaseOrderDetail
SET ProductID = NULL
COMMIT TRANSACTION
GOIf you don’t want to carry the old column around you can go through table copy and rename dance described in the first upgrade strategy to delete the column. In this case, however, you don’t need the whole strategy, just the T-SQL itself since no one is using the old column.
The fifth upgrade phase will clean-up the database without touching the application code.