CLR offers an excellent construct for parallel programming – a task. Instead of dealing with threads, developers only have to break their code into small parallelizable units of work, and magic happens behind the scenes. Tasks run on the default thread pool under the careful watch of the default task scheduler. C# compiler has a convenient syntactic sugar “async” and “await” that break up monolithic methods into resumable state machines. Life is great until two worlds collide and a poor developer is staring down the barrel of a choice. When synchronous code transitions into asynchronous it is very tempting to just type “Task.Result” or “Task.Wait()“. This split-second, almost unconscious decision may carry drastic consequences for your app. In this article we will see why “await Task” is almost always the right choice, even if highly disruptive.
Task.Wait() shifts the bottleneck upstream to the thread pool
Thread pool contention is a well-known challenge to seasoned developers. Services should process work at the same rate as they receive it. If they aren’t then they drag a bunch of additional work that slows down the system:
- Slow services need protection with request throttling in front of them to keep them from grinding to a halt.
- Service with internal contention, increase hardware demands – either need beefier computers or more of them or both.
In this paragraph, we will look at a sample application that makes a network IO request on each task. This is obviously a gross oversimplification with a number of assumptions (about the relative cost and latency of network IO when compared to the rest of the code).
using System;
using System.Diagnostics;
using System.Net.Http;
using System.Threading;
using System.Threading.Tasks;
namespace TaskTest
{
class Program
{
private static async void EvaluateSyncVsAsync()
{
Stopwatch watch = new Stopwatch();
watch.Start();
while (watch.Elapsed < TimeSpan.FromSeconds(60))
{
Task.Run(async () => { await ExecuteTaskAsync(); });
Thread.Sleep(TimeSpan.FromMilliseconds(2));
}
}
private static async Task ExecuteTaskAsync()
{
using (HttpClient client = new HttpClient())
{
try
{
await client.GetAsync(new Uri("https://nuget.org/"));
}
catch (Exception e)
{
Console.WriteLine("{0}", e.Message);
}
}
}
static void Main(string[] args)
{
EvaluateSyncVsAsync();
}
}
}
Every 2 milliseconds this application schedules a task to go fetch the home page of an arbitrarily selected website. It takes approximately 900 milliseconds to establish TLS and fetch the home page. As such, the bottleneck in this workflow is the network, not the application. We will conduct experiments on powerful hardware – Core i7 6-core CPU hyperthreaded, 32GB of RAM, 1 Gigabit NIC. We will use dotnet-counters tool to capture basic performance counters of CLR as follows:
dotnet-counters collect -n TaskTest --refresh-interval 1 --counters System.Runtime[threadpool-thread-count,threadpool-queue-length,threadpool-completed-items-count] --format csv -o counters_async.csvAsynchronous mode
When we run the application as written above we see a constant scale. Application primes the thread pool within a second and after that point has no queue wait time as well as continuously declining thread pool size. Peek thread pool allocation is 28 threads. This application was able to complete over 3200 successful requests in 60 seconds.
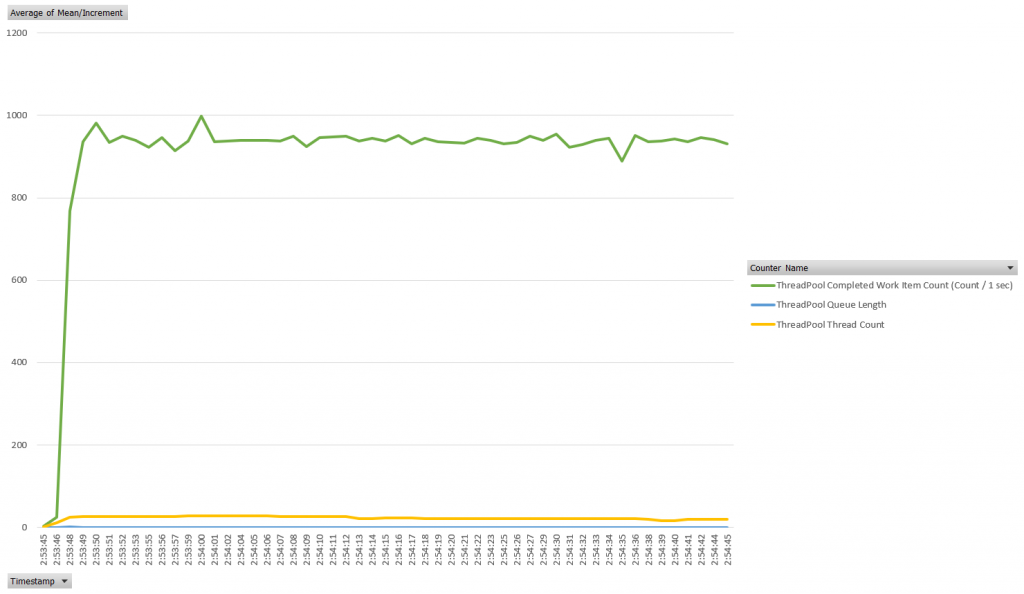
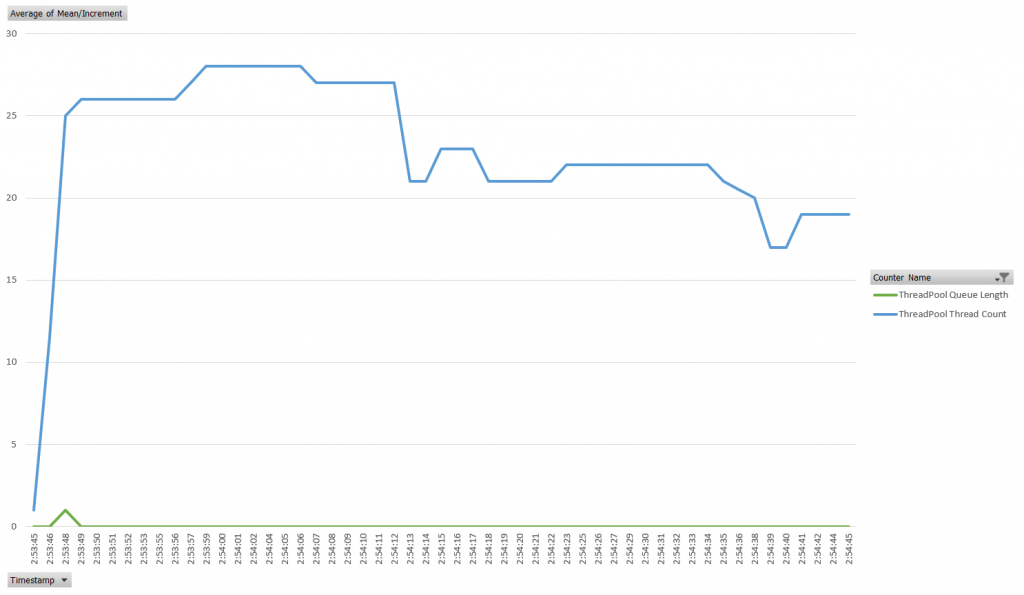
Synchronous bottleneck
Now we are going to introduce a bottleneck in the thread pool by replacing “await” with “.Wait()“. This will increase the demand for threads because each top-level thread will now be waiting on a synchronous event, depriving the thread pool of threads to process HttpClient continuations.
private static async Task ExecuteTaskAsync()
{
using (HttpClient client = new HttpClient())
{
try
{
// Converted the code to synchronous to introduce the bottleneck intentionally.
// Do not do this in your code.
client.GetAsync(new Uri("https://nuget.org/")).Wait();
}
catch (Exception e)
{
Console.WriteLine("{0}", e.Message);
}
}
}Thread pool scheduler has to allocate additional threads to keep up with demand so we are seeing thread count rising significantly above the previous levels. We are also seeing queue length increasing significantly – this metric represents the number of units of work waiting for a thread to run.
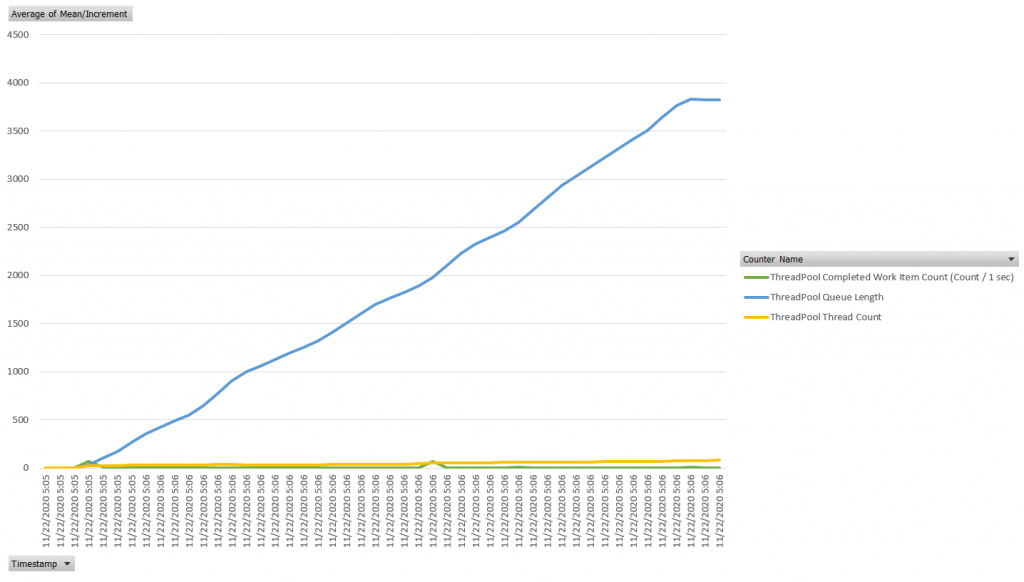
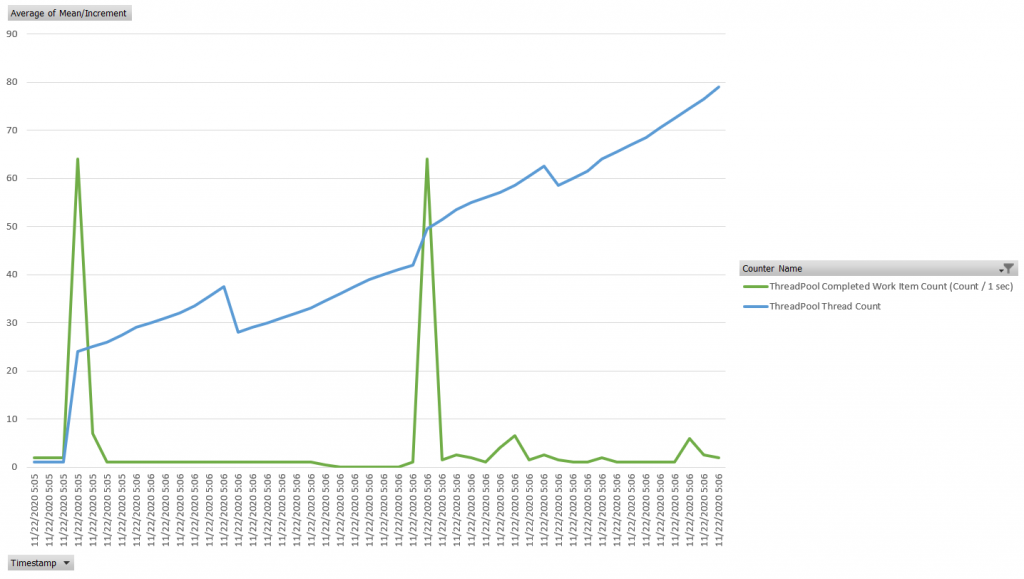
This is clearly a resource-consuming application design with low throughput. In total, in 60 seconds this application completed only 12 successful requests – that’s 250x times slower than a fully asynchronous application.
Thread pool manager based on the Hill Climb algorithm is ineffective for bursty workloads
There is a lot of “magic” behind the scenes in CLR (native) and managed foundational libraries to create an illusion of workload elasticity. In plan English – to know how many threads to allocate for any moment in time to handle the work items queued-up in the thread pool is not easy. One has to strike a balance between the two extremes:
- Too few threads will cause thread pool contention as items will be sitting waiting for a thread to become available
- Too many threads will cause an increase in context switches and reduce data locality. It means that CPU caches will become less effective and your program will need to make round-trips to RAM more often. There’s a great break-down of latencies between caches and RAM from Jonas Boner.
CLR uses the Hill Climb heuristic to find the global throughput maxima through the thread pool. It is worth taking a minute to study the following theoretical material:
- Concurrency – Throttling Concurrency in the CLR 4.0 ThreadPool
- Optimizing Concurrency Levels in the .NET ThreadPool: A Case Study of Controller Design and Implementation
Implementation of this algorithm inside Core CLR is available in the public GitHub repository. Matt Warren published by far the best explanation of how the Hill Climb works in his The CLR Thread Pool ‘Thread Injection’ Algorithm post, section “Working with the Hill Climbing code”.
Simulation
In the previous paragraph, we already established that Task.Wait() causes contention. In this paragraph, we have learned that Hill Climb adjusts the thread count iteratively until throughput cannot be increased. Task.Wait() doubles the effect of any contention that exists in the thread pool. Let’s see how Hill Climb reacts to sudden spikes in load simulated by simple Thread.Sleep().
using System;
using System.Threading;
using System.Threading.Tasks;
namespace TaskTest
{
class Program
{
private static async void EvaluateSyncVsAsync()
{
Stopwatch watch = new Stopwatch();
watch.Start();
while (watch.Elapsed < TimeSpan.FromSeconds(60))
{
// Submit a batch of work items with normally distributed "load" duration all at once
for (int i = 0; i < 10000; i++)
{
Task.Run(async () => { await ExecuteAsyncComputation(); });
}
// Simulate workload spike that occurs every 10 seconds
Thread.Sleep(TimeSpan.FromSeconds(10));
}
}
private static async Task ExecuteAsyncComputation()
{
Random random = new Random(Environment.TickCount);
// Simulate random load
Thread.Sleep(TimeSpan.FromMilliseconds(1 + random .Next(0, 10)));
}
static void Main(string[] args)
{
EvaluateSyncVsAsync();
}
}
}
This application induces the desired effect on the thread pool – we see 6 spikes of load expressed as a Queue Length (leading indicator), followed by a spike of Completed Work Item Count per second (trailing indicator). Two interesting characteristics worth paying attention to:
- How high the Queue Length spikes on every iteration is indicative of whether the thread pool is adequately primed for the workload
- The amount of time between the spike in the Queue Length and the spike in the Completed Work Item, which indicates how quickly Hill Climb reacts to the workload
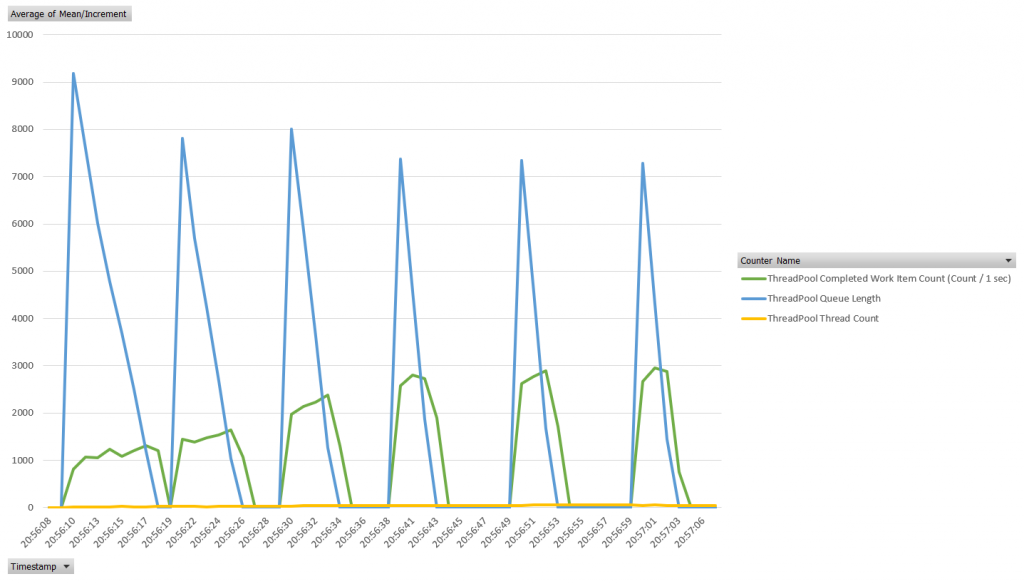
Here’s the length of time when the Queue Length was greater than zero during each burst: 8 seconds, 6 seconds, 5 seconds, 3 seconds, 3 seconds, and 3 seconds correspondingly. The best algorithm was able to do was 3 seconds of processing time. Exactly 10,000 tasks were queued in 1-2 seconds during each burst. However, at no point in time, the algorithm matched the demand strictly. We can even see that after each burst, a 10-second delay was enough for the Hill Climb to start deallocating threads.
Locks and deadlocks
Synchronization mechanisms that exist in the OS are designed for threads. They do not have a concept of lock delegation from one thread to another if the workflow transitions between them. These synchronization mechanisms are exposed in .NET as ManualResetEvent, Monitor, Semaphore, Mutex, etc.
Tasks are CLR constructs that the underlying OS doesn’t see. It sees a bunch of threads doing a bunch of work. Everything that encapsulates a task is done by foundational libraries – installation of impersonation and synchronization context, async locals, etc. A decent amount of glue code is written by the .NET runtime developers to bring thread-wide concepts to tasks when tasks can jump between threads continuation after continuation – see ExecutionContext.RunInternal(), for example. Clearly, the thread-based synchronization approach doesn’t work for tasks.
SemaphoreSlim is a popular async synchronization primitive. It doesn’t look at the thread on which it runs, it simply counts the number of tasks that gained access under the semaphore, which makes it portable across continuations. This behavior explains why the following code deadlocks.
private static async Task ExecuteAsyncTask()
{
await Semaphore.WaitAsync();
// Delegate to another task that will try to enter the semaphore while this task is holding it
await ExecuteNestedAsyncTask();
try
{
// ... Asynchronous code ...
}
finally
{
Semaphore.Release();
}
}
private static async Task ExecuteNestedAsyncTask()
{
// Deadlock occurs here because Semaphore is not re-entrant even within the same continuation chain
// Do not do this in your code
await Semaphore.WaitAsync();
try
{
// ... Asynchronous code ...
}
finally
{
Semaphore.Release();
}
}To reconcile Tasks and Threads in .NET runtime there is a concept of SynchronizationContext. It was introduced to deal with things like UI thread in Windows and ASP.NET worker thread managed by IIS that handle the request pipeline. The idea is that only some threads can perform certain actions but not the others. Every time a task chain completes it must return control to that thread. Stephen Cleary did a great job explaining how deadlocks occur when those special threads are blocked with Task.Wait() in his Don’t Block on Async Code post.
There two general approaches to break synchronization context boundary and avoid a deadlock. See ConfigureAwait FAQ for a deep dive into the topic.
- Task.ConfigureAwait(continueOnCapturedContext: false) is recommended within general-purpose library code. However, UI applications must continue on the original synchronization context or they will be busted.
- Task.Run(() => {…}) will also break the synchronization context, but it will also break the task scheduler boundary. If your application uses a custom task scheduler this will force the next task to run on the default task scheduler.
Awaiting a Task unwraps AggregateException
As developers, we are very careful about our API contracts. We want to control which exceptions get the fly out of our methods – we test and document them. Depending on whether we Task.Wait() or await Task we end-up throwing a different exception.
private static async void EvaluateSyncVsAsync()
{
try
{
// This line will see "InvalidOperationException"
await ExecuteAnotherTask();
}
catch (Exception ex)
{
Console.WriteLine("Caught: {0}", ex);
}
}
private static async Task ExecuteAnotherTask()
{
// ... async code ...
throw new InvalidOperationException("Operation was invalid");
}Awaited code will produce the following output:
Caught: System.InvalidOperationException: Operation was invalid
at TaskTest.Program.ExecuteAnotherTask() in C:\Users\Oleg\source\repos\TaskTest\TaskTest\Program.cs:line 37
at TaskTest.Program.EvaluateSyncVsAsync() in C:\Users\Oleg\source\repos\TaskTest\TaskTest\Program.cs:line 19A seemingly benign change that switches code to go synchronous will impact our API contract, if not handled appropriately.
// This line will see "AggregateException"
ExecuteAnotherTask().Wait();
This code no longer unwraps AggregateException.
Caught: System.AggregateException: One or more errors occurred. (Operation was invalid)
---> System.InvalidOperationException: Operation was invalid
at TaskTest.Program.ExecuteAnotherTask() in C:\Users\Oleg\source\repos\TaskTest\TaskTest\Program.cs:line 37
--- End of inner exception stack trace ---
at System.Threading.Tasks.Task.ThrowIfExceptional(Boolean includeTaskCanceledExceptions)
at System.Threading.Tasks.Task.Wait(Int32 millisecondsTimeout, CancellationToken cancellationToken)
at System.Threading.Tasks.Task.Wait()
at TaskTest.Program.EvaluateSyncVsAsync() in C:\Users\Oleg\source\repos\TaskTest\TaskTest\Program.cs:line 19Too much async will hurt application performance
We’ve been preaching an async pattern like a universal panacea to all development problems in this article. Yet, there are a few cases where too much async is not healthy and you’re better off going synchronous. You should aim to strike a balance between the amount of computing spent within each task relative to the cost of task switching and handling in the thread pool and scheduler.
Avoid await unless it is necessary
Let’s look at a contrived example of chained await calls that don’t add value on their own, but rather exist to chain async calls. For each method, the compiler will generate an IAsyncStateMachine class. Each state machine will have a MoveNext() method that links to a TaskAwaiter from the next method.
private static async Task A()
{
await B();
}
private static async Task B()
{
await C();
}
private static async Task C()
{
await D();
}
private static async Task D()
{
await File.WriteAllTextAsync("D.txt", "Great content");
}
Each method will be resumable with all the results and exception handling code prepared for it. For a method that doesn’t have any useful code that’s awful a lot of compiler-generated code that will consume CPU at runtime. A better approach is to collapse a bunch of asynchronous methods into synchronous ones that return the final task to the top.
private static Task A()
{
return B();
}
private static Task B()
{
return C();
}
private static Task C()
{
return D();
}
private static Task D()
{
return File.WriteAllTextAsync("D.txt", "Great content");
}
The modified code version doesn’t have any async syntactic sugar but is functionally equivalent to the code at the top. It has better runtime performance due to reduced CPU and memory consumption. Even non-async methods can be awaited as long as they return a Task.
Exception handling in Task is expensive
Tasks have a reasonable performance on the happy path – when every continuation does it’s thing and hands control to the next continuation. Tasks have a layer of glue that runs on every continuation to configure synchronization and impersonation context, which is reasonably optimized. However, when a task fails it goes into berserk mode trying to create that masterpiece of an exception that we all love and expect from .NET.
Inside the execution context, Task calls ExceptionDispatchInfo.Capture(), which in turn calls Exception.CaptureDispatchState(), which calls GetStackTracesDeepCopy(). This method attempts to construct a meaningful stack trace for an exception across all task continuations, including all the glue code injected by .NET core library. That’s a very compute and memory intense operation. If for your app exceptions are rare then this is no big deal – you really want that specific stack trace to debug the problem. However, if exceptions occur in your code often, this will become a significant drag on application performance.
It is best to design your application in exception-free manner and replace all calls on the happy path that can throw with TrySomething() pattern.
Credits
Thanks to dotnetCoreLogoPack for .NET Core logo.